
Ukrainian energy provider targeted by Industroyer2 – ESET helps disrupt Zloader botnets – Where do new ideas come from and how are they spread?
The post Week in security with Tony Anscombe appeared first on WeLiveSecurity

Ukrainian energy provider targeted by Industroyer2 – ESET helps disrupt Zloader botnets – Where do new ideas come from and how are they spread?
The post Week in security with Tony Anscombe appeared first on WeLiveSecurity

ESET researchers provided technical analysis, statistical information, and known command and control server domain names and IP addresses
The post ESET takes part in global operation to disrupt Zloader botnets appeared first on WeLiveSecurity

Attestations play a large role in SLSA and it’s essential that consumers of artifacts know where to find the attestations for those artifacts.
Acme really likes this approach because the attestations are always available and it doesn’t introduce any new dependencies.
Though the latency of querying attestations from Rekor is likely too high for doing verification at time of use, Oppy isn’t too concerned since they expect users to query Rekor at install time.
Hybrid
A hybrid model is also available where the publisher stores the attestations in Rekor as well as co-located with the artifact in the repo—along with Rekor’s inclusion proof. This provides confidence the data was added to Rekor while providing the benefits of co-locating attestations in the repository.
‘Policy’ refers to the rules used to determine if an artifact should be allowed for a use case.
Policies often use the package name as a proxy for determining the use case. An example being, if you want to find the policy to apply you could look up the policy using the package name of the artifact you’re evaluating.
Policy specifics may vary based on ease of use, availability of data, risk tolerance and more. Full verification needs more from policies than delegated verification does.
Default policies allow admission decisions without the need to create specific policies for each package. A default policy is a way of saying “anything that doesn’t have a more specific policy must comply with this policy”.
Squirrel plans to eventually implement a default policy of “any package without a more specific policy will be accepted as long as it meets SLSA 3”, but they recognize that most packages don’t support this yet. Until they achieve critical mass they’ll have a default SLSA 0 policy (all artifacts are accepted).
While Oppy is leaving verification to their users, they’ll suggest a default policy of “any package built by ‘https://oppy.example/slsa/builder/v1’”.
Squirrel also plans to allow users to create policies for specific packages. For example, this policy requires that package ‘foo’ must have been built by GitHub Actions, from github.com/foo/acorn-foo, and be SLSA 4.
Squirrel will also allow packages to create SLSA 0 policies if they’re not using SLSA compliant infrastructure.
Policy evaluation could do more than just evaluate the SLSA requirements. The same policies that check SLSA requirements are well placed to check other properties that are important to organizations like “was static analysis performed”, “are there any known CVEs in this artifact”, “was integration testing successful”, etc…
Acme is really interested in some of these policy add-ons. They’d like to avoid the embarrassing situation of publishing a new container image with known CVEs. They’re not sure how to implement it yet but they’ll be on the lookout for tools that can help them do so.
When using specific, non-default, policies verifiers need to know where to find the policy they need to evaluate.
Squirrel plans to store specific policies as a property of the package in the repository. This makes them very easy for users and their tooling to find. It also allows the maintainer of the package to easily set the policy (they already have write permissions!).
A potential downside is that the write permissions are the same as for the package itself. An attacker that compromises the developer’s credentials could also change the policy. This may not be as bad as it seems. Policies are human-readable so anyone paying attention would notice that package foo’s policy now says that it can be built from github.com/not-foo/acorn-foo. Squirrel plans to notify interested parties (including the maintainer!) when the policy changes, potentially letting them “sound the alarm” if anything nefarious happens.
A similar approach is taken in a number of contact-change workflows. For example, when you change your address with your bank, the bank will send you an email (and a letter to the old address) letting you know the address has been changed. This type of notification would alert the maintainer to a potential compromise.
Squirrel would also consider requiring a second person to review any policy changes for packages with over 10,000 users.
Another option might be to just create a canonical git repo (e.g. github.com/slsa-framework/slsa-acorn-policies) and let people publish proposed policies there. This has the advantage of using a separate ACL control mechanism from the package repository itself, but the disadvantages of being difficult to ensure the author of the policy is actually allowed to set the policy for that package and not scaling well as the repo grows.
The approach outlined in policy auto generation could help here. Automation in the repo could just look at the last N releases of the package and determine if the proposed policy matches what’s actually been published. Proactive changes to the policy (like deciding to switch from GitHub Actions to CircleCI) would be harder to coordinate however.
Organizations can also use their policy repo to vet any upstream changes to policy and potentially add additional checks (e.g. “doesn’t have any known vulnerabilities”).
Squirrel plans to make use of this by making VSAs available for each artifact published, publicizing their verifier ID (i.e. ‘https://squirrel.example/slsa-verifier’) and the public key used to sign the VSAs. They even plan to build VSA verification directly into the Squirrel tooling, so that users can get SLSA protection by default.
While Acme is happy to use Squirrel’s verifier (and the verification built into the tooling) they still need their own verifier so they can publish VSAs to Acme customers. So Acme plans to stand up their own verification service and publish their verifier ID (i.e. ‘https://acme.example/private-verifier’) and signing key. Acme customers can then verify the software they get from Acme.
In the future Acme could require all software used throughout the company to be verified with this verifier (instead of relying on public verifiers). They’d do the verification and generate VSAs whenever artifacts are imported into their private Artifactory instance. They could then configure this ID/key pair for use throughout Acme and be confident that any software used has been verified according to Acme policy. That’s not Acme’s highest priority at the moment, but they like having this option open to them.
When using delegated verification this could be the easiest case. Squirrel can just build the key they used for delegated verification directly into the Squirrel tooling. Acme can also fairly easily configure the use of their keys through the company using existing configuration control mechanisms.
When using full verification this can be harder. If there are multiple builders that could be accepted the keys that sign the attestations need to be distributed to everyone that might use that builder. For Squirrel this would be really difficult since they plan to allow package maintainers to use whatever builder they want. How those keys get configured would be tricky just for Squirrel, and much more difficult if downstream Squirrel users wanted to do full verification of the Squirrel packages.
The situation is easier, however, for Oppy. That’s because Oppy plans to only accept artifacts built by their autobuilder network. Oppy can configure this network to use a single (or small set) of keys and then publish those keys (and the SLSA level Oppy believes it meets) for downstream users.
Squirrel plans to solve the problem of which keys they accept by leveraging Fulcio. Squirrel will build support for Fulcio root keys into their verifier and then express which Fulcio subject is allowed to sign attestations in the specific policy of each package. E.g. “Squirrel package ‘foo’ must have been built & signed by ‘spiffe://foobar.com/foo-builder, from github.com/foo/acorn-foo, and be SLSA 4”.
The Update Framework (TUF)
The above methods could be further enhanced with TUF to allow the secure maintenance of keys. TUF metadata could include all the SLSA keys, the build services and other entities they’re valid for, and the SLSA levels they’re qualified at. Oppy is considering using TUF to let verifiers securely fetch and update keys used by the Autobuilder network. Oppy would use a TUF delegation to indicate that these keys should only be used for the builder id ‘https://oppy.example/slsa/builder/v1’. Squirrel might do something similar to allow for updating the Fulcio key in its tooling.
Acme wants to record and verify the dependencies that go into its container into the SLSA provenance. Acme would prefer that this functionality were just built-in their build service, but that feature isn’t available yet. Instead they’ll need to do something themselves. They have a few options at their disposal:
A downside is that this approach, if run in the build itself, is not guaranteed to be complete and cannot meet the “non-falsifiable” requirement (since the results reported by the wrapper could be falsified by the build process), relegating this approach to SLSA 2. Still, it allows Acme to make progress SLSA-fying their builds and provides a starting point for achieving higher SLSA levels.
Since Squirrel does build verification into their tooling, Acme can just use acorn install to verify the dependencies and record what was installed. Acme can use this information to populate the Squirrel packages installed in the materials section of the provenance and it can include the attestations of those dependencies in the in-toto bundle for their container image.
As with tool wrappers, if this method is used in the build itself it cannot meet “non-falsifiable” requirement.
In the first two parts of this series, we’ve covered the basics of getting started with SLSA and the details of policy and provenance storage, policy verification, and key handling. In our next post we’ll cover how Squirrel, Oppy, and Acme put this all together to protect a heterogeneous supply chain.

If you look back at the long arc of history, it’s clear that one of the most crucial drivers of real progress in society is innovation
The post Innovation and the Roots of Progress appeared first on WeLiveSecurity
One of the great benefits of SLSA (Supply-chain Levels for Software Artifacts) is its flexibility. As an open source framework designed to improve the integrity of software packages and infrastructure, it is as applicable to small open source projects as to enterprise organizations. But with this flexibility can come a bewildering array of options for beginners—much like salsa dancing, someone just starting out might be left on the dance floor wondering how and where to jump in.
Though it’s tempting to try to establish a single standard for how to use SLSA, it’s not possible: SLSA is not a line dance where everyone does the same moves, at the same time, to the same song. It’s a varied system with different styles, moves, and flourishes. The open source community, organizations, and consumers may all implement SLSA differently, but they can still work with each other.
In this three-part series, we’ll explore how three fictional organizations would apply SLSA to meet their different needs. In doing so, we will answer some of the main questions that newcomers to SLSA have:
Part 1: The basics
Part 2: The details
Part 3: Putting it all together
Our fictional example involves three organizations that want to use SLSA:
Squirrel: a package manager with a large number of developers and users
Oppy: an open source operating system with an enterprise distribution
Acme: a mid sized enterprise.
Squirrel wants to make SLSA as easy for their users as possible, even if that means abstracting some details away. Meanwhile, Oppy doesn’t want to abstract anything away from their users under the philosophy that they should explicitly understand exactly what they’re consuming.
Acme is trying to produce a container image that contains three artifacts:
This series demonstrates one approach to using SLSA that lets Acme verify the Squirrel and Oppy packages ‘foo’ and ‘baz’ and its customers verify the container image. Though not every suggested solution is perfect, the solutions described can be a starting point for discussion and a foundation for new solutions.
In order to SLSA, Squirrel, Oppy, and Acme will all need SLSA capable build services. Squirrel wants to give their maintainers wide latitude to pick a builder service of their own. To support this, Squirrel will qualify some build services at specific SLSA levels (meaning they can produce artifacts up to that level). To start, Squirrel plans to qualify GitHub Actions using an approach like this, and hopes it can achieve SLSA 4 (pending the result of an independent audit). They’re also willing to qualify other build services as needed. Oppy on the other hand, doesn’t need to support arbitrary build services. They plan to have everyone use their Autobuilder network which they hope to qualify at SLSA 4 (they’ll conduct the audit/certification themselves). Finally, Acme plans to use Google Cloud Build which they’ll self-certify at SLSA 4 (pending the result of a Google-conducted audit).
Squirrel, Oppy, and Acme will follow a similar qualification process for the source control systems they plan to support.
Full verification
At some point, one or more of the organizations will need to do full verification of each artifact to determine if it is acceptable for a given use case. This is accomplished by checking if the artifact meets the appropriate policy.
Typically, full verification would take place with SLSA provenance, source attestations, and perhaps other specialized attestations (like vulnerability scan results). While having to coordinate this data for all of its dependencies seems like a lot of work to Acme, they’re prepared to do full verification if Squirrel and Oppy are unable to.
When Acme isn’t using full verification, they can instead use delegated verification where they check if an artifact is acceptable for a use case by checking if some other trusted party who performed a full verification (such as Squirrel or Oppy) believes the artifact is acceptable.
Delegated verification is easier to perform quickly with limited data and network connectivity. It may also be easier for some users who value if someone they trust verified the artifact is good.
Squirrel likes how easy delegated verification would make things for their users and plans to support it by creating a Verification Summary Attestation (VSA) when they perform full verification.
Verification (full or delegated) could happen at a number of different times.
Squirrel plans to perform full verification when an artifact is published to their repo. This will ensure that packages in the repo have met their corresponding policy. It’s also helpful because all the required data can be gathered when latency isn’t critical.
If this were the only time verification is performed, it would put the repository’s storage in the trusted computing base (TCB) of its users. Squirrel’s plans to use delegated verification (and issue VSAs) can prevent this. The signature on the VSA will prevent the artifacts from being tampered with while sitting in storage, even if they’re just SLSA 0. Downstream users will just need to verify the VSA.
Acme also wants to do some sort of verification on the import to their internal repo since it simplifies their security story. They’re not quite sure what this will look like yet.
Acme also wants to do verification when an artifact is actually installed since it can remove a number of intermediaries from their TCB (their repo, the network, upstream storage systems).
If they perform full verification at install then they must gather all the required information. That could be a lot of data, but it might be simplified by gathering the data from external sources and caching it in their internal repo. A larger problem is that it requires Acme to have established trust in all parties that produced that information (e.g. every builder of every package). For a complex supply chain that may be difficult.
If Acme performs delegated verification, they only need the VSA for the packages being installed and to explicitly trust a handful of parties. This allows the complex full verification to be performed once while allowing all users of that package to perform a much simpler operation.
Given these tradeoffs Acme prefers delegated verification at install time. Squirrel also really likes the idea and plans to build install time verification directly into the Squirrel tool.
Time of use verification allows the most context with which decisions can be made (“is this job allowed to run this code and is it free from vulns right now?”). It also allows policy changes to affect already built & installed software (which may or may not be desirable).
Acme wants their users to be able to verify on use without too many dependencies so they plan to provide VSAs users can use to perform delegated verification when they start the container (perhaps using something like Kyverno).
Inevitably a build or system may require that an artifact without ‘original’ provenance is used. In these cases it may be desirable for the importer to generate provenance that details where it got this artifact. For example, this generated provenance shows that http://example.com/foo.tgz with sha256:abc was imported by ‘auto-importer’:

Such an artifact would likely not be accepted at higher SLSA levels, but the provenance can be used to: 1) prevent tampering with the artifact after it’s been imported and 2) be a data point for future analysis (e.g. should we prioritize asking for foo.tgz to be distributed with native SLSA provenance?).
Acme might be interested in taking this approach at some point, but they don’t need it at the moment.
In our next post we’ll cover specific approaches that can be used to answer questions like “where should attestations and policies be stored?” and “how do I trust the attestations that I receive?”
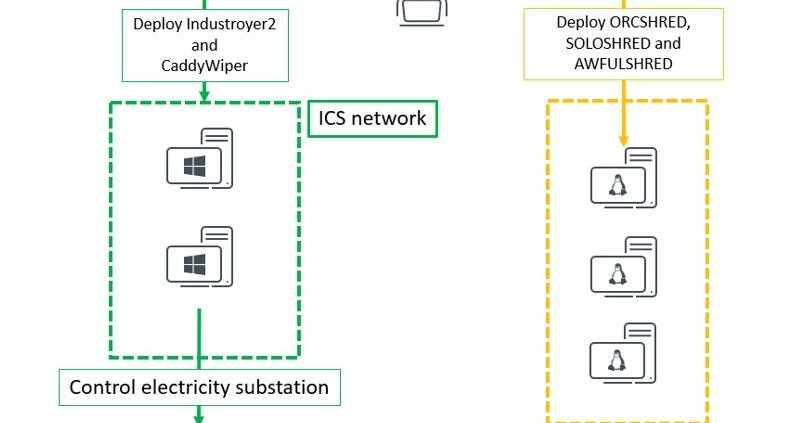
This ICS-capable malware targets a Ukrainian energy company
The post Industroyer2: Industroyer reloaded appeared first on WeLiveSecurity

Fake e-shops & Android malware – A journey into the dark recesses of the world wide web – Keeping your cloud resources safe
The post Week in security with Tony Anscombe appeared first on WeLiveSecurity
As cloud systems are increasingly the bedrock on which digital transformation is built, keeping a close eye on how they are secured is an essential cybersecurity best practice
The post How secure is your cloud storage? Mitigating data security risks in the cloud appeared first on WeLiveSecurity
Many of the recent high-profile software attacks that have alarmed open-source users globally were consequences of supply chain integrity vulnerabilities: attackers gained control of a build server to use malicious source files, inject malicious artifacts into a compromised build platform, and bypass trusted builders to upload malicious artifacts.
Each of these attacks could have been prevented if there were a way to detect that the delivered artifacts diverged from the expected origin of the software. But until now, generating verifiable information that described where, when, and how software artifacts were produced (information known as provenance) was difficult. This information allows users to trace artifacts verifiably back to the source and develop risk-based policies around what they consume. Currently, provenance generation is not widely supported, and solutions that do exist may require migrating build processes to services like Tekton Chains.
This blog post describes a new method of generating non-forgeable provenance using GitHub Actions workflows for isolation and Sigstore’s signing tools for authenticity. Using this approach, projects building on GitHub runners can achieve SLSA 3 (the third of four progressive SLSA “levels”), which affirms to consumers that your artifacts are authentic and trustworthy.
SLSA (“Supply-chain Levels for Software Artifacts”) is a framework to help improve the integrity of your project throughout its development cycle, allowing consumers to trace the final piece of software you release all the way back to the source. Achieving a high SLSA level helps to improve the trust that your artifacts are what you say they are.
This blog post focuses on build provenance, which gives users important information about the build: who performed the release process? Was the build artifact protected against malicious tampering? Source provenance describes how the source code was protected, which we’ll cover in future blog posts, so stay tuned.
To create tamperless evidence of the build and allow consumer verification, you need to:
The full isolation described in the first two points allows consumers to trust that the provenance was faithfully recorded; entities that provide this guarantee are called trusted builders.
Our Go prototype solves all three challenges. It also includes running the build inside the trusted builder, which provides a strong guarantee that the build achieves SLSA 3’s ephemeral and isolated requirement.
Running the workflow on GitHub-hosted runners gives the guarantee that the code run is in fact the intended workflow, which self-hosted runners do not. This prototype relies on GitHub to run the exact code defined in the workflow.
The reusable workflow also protects against possible interference from maintainers, who could otherwise try to define the workflow in a way that interferes with the builder. The only way to interact with a reusable workflow is through the input parameters it exposes to the calling workflow, which stops maintainers from altering information via environment variables, steps, services and defaults.
To protect against the possibility of one job (e.g. the build step) tampering with the other artifacts used by another job (the provenance step), this approach uses a trusted channel to protect the integrity of the data. We use job outputs to send hashes (due to size limitations) and then use the hashes to verify the binary received via the untrusted artifact registry.
OpenID Connect (OIDC) is a standard used across the web for identity providers (e.g., Google) to attest to the identity of a user for a third party. GitHub now supports OIDC in their workflows. Each time a workflow is run, a runner can mint a unique JWT token from GitHub’s OIDC provider. The token contains verifiable information of the workflow identity, including the caller repository, commit hash, trigger, and the current (reuseable) workflow path and reference.
Using OIDC, the workflow proves its identity to Sigstore’s Fulcio root Certificate Authority, which acts as an external verification service. Fulcio signs a short-lived certificate attesting to an ephemeral signing key generated in the runner and tying it to the workload identity. A record of signing the provenance is kept in Sigstore’s transparency log Rekor. Users can use the signing certificate as a trust anchor to verify that the provenance was authenticated and non-forgeable; it must have been created inside the trusted builder.
See an example in action in the official repository.
Performing these steps guarantees to the consumer that the binary was produced in the trusted builder at a given commit hash attested to in the provenance. They can trust that the information in the provenance was non-forgeable, allowing them to trust the build “recipe” and trace their artifact verifiably back to the source.
One extra benefit of this method is that maintainers don’t need to manage or distribute cryptographic keys for signing, avoiding the notoriously difficult problem of key management. The OIDC protocol requires no hardcoded, long-term secrets be stored in GitHub’s secrets, which sidesteps the potential problem of key mismanagement invalidating the SLSA provenance. Consumers simply use OIDC to verify that the binary artifact was built from a trusted builder that produced the expected provenance.
Utilizing the SLSA framework is a proven way for ensuring software supply-chain integrity at scale. This prototype shows that achieving high SLSA levels is easier than ever thanks to the newest features of popular CI/CD systems and open-source tooling. Increased adoption of tamper-safe (SLSA 3+) build services will contribute to a stronger open-source ecosystem and help close one easily exploited gap in the current supply chain.
We encourage testing and adoption and welcome any improvements to the project. Please share feedback, comments and suggestions at slsa-github-generator-go and slsa-verifier project repositories. We will officially release v1 in a few weeks!
In follow-up posts, we will demonstrate adding non-forgeable source provenance attesting to secure repository settings, and showcase the same techniques for other build toolchains and package managers, etc. Stay tuned!
ESET researchers analyzed three malicious applications targeting customers of eight Malaysian banks
The post Fake e‑shops on the prowl for banking credentials using Android malware appeared first on WeLiveSecurity
